redis性能优化骚操作——绑核
一、现代CPU模式
现代一个CPU中,可以有多个运行核心(称之为物理核),每个物理核都有自己独立的一级缓存(L1)和二级缓存(L2)。并且每个物理核一般会有两个超线程(称之为逻辑核);同一个物理核下的两个逻辑核同享L1和L2缓存。并且现在机器主流都是多CPU处理器结构(CPU Socket),每个CPU拥有自己的L1和L2以及L3级缓存和自己所管理的内存空间;不同处理器之间通过总线进行连接。一台机器的cpu构造如下图所示:

二、cpu多核对redis的影响
因为我们的cpu存在上下文切换(context switch),每个物理核有自己独立的L1和L2级缓存,程序执行最频繁的指令和数据会被缓存到L1和L2级缓存中,一旦我们的程序被切换到另一个物理核时,对应的指令和数据需要被重新刷到对应的(L1、L2)缓存中,所以频繁进行上下文切换的话,程序就不能很好的利用L1和L2级缓存,就会增加程序的延时性。针对这个频繁切换cpu核进行操作,我们可以采用绑核操作,将一个redis实例只在对应的物理核上执行,不会切换到其他物理核上。
taskset -c 0 ./redis-server三、多cpu对redis的影响
我们的程序被cpu执行都是通过时间片,一台机器上有多个应用时,某一时刻是有一个程序可以获取cpu去执行程序代码,所以当一个程序在一个CPU socket运行时,如果此时发生了CPU切换,程序被切换到另一个CPU socket上运行,此时程序在运行时读取内存数据时,需要读取到之前的cpu socket所管理的内存,这种访问属于远端内存访问。这种访问 Socket 直接连接的内存相比,远端内存访问会增加应用程序的延迟。
所以多cpu对redis的影响:
因为L1,L2缓存中的指令和数据可以提高访问速度,一旦发生了cpu的切换,同样的指令和数据需要重新加载到L1和L2缓存中,影响redis的性能。
因为每个cpu都有自身控制的内存,一旦发生cpu的切换,就会存在一个cpu需要访问另一个cpu所管理的内存,出现远端内存的访问情况,影响redis的响应时间。
首先我们的redis实例需要很好的网络性能,redis是如何和操作系统的网络中断程序进行交互的呢?

网络中断程序从网卡中读取数据,并将数据写入到操作系统的内核缓冲区中,内核会通过epoll机制触发事件,通知到redis实例,redis就会从内核中拉取数据,复制到自己的内存空间中。这个时候就会存在一个潜在影响性能的点,到redis实例和网络中断处理程序,在不同的CPU Socket中运行时,redis读取网络数据时,就需要跨CPU Socket运行,影响其性能,其流程如下:
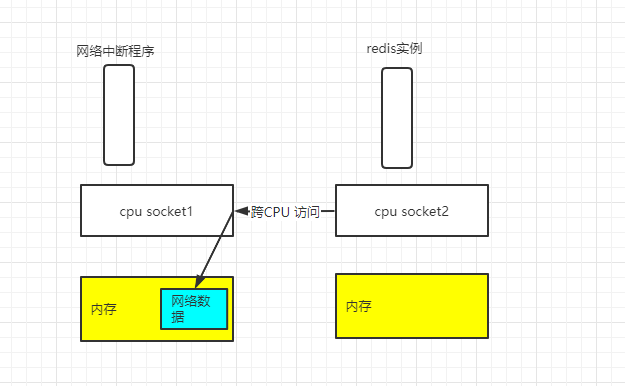
所以为了避免redis跨cpu访问网络数据,需要将redis实例和网络中断程序,绑定在同一个CPU Socket中:

四、绑核存在的风险点
当我们将redis实例绑在一个cpu核上时,redis其后台线程和fork的子进程等都会和redis主线程抢占cpu资源,导致redis主线程变慢,影响性能。
针对这个问题:主要的解决方法有两种:
一个就是redis实例对应绑一个物理核,因为我们的cpu一个物理核有两个逻辑核,这样可以把我们的两个逻辑核都给用上,可以在一定程度上缓解cpu的资源竞争。
修改redis源代码,把子进程和后台线程绑到不同的CPU核上。