文章系转载,便于整理和分类,原文地址:https://cloud.tencent.com/developer/article/1997421基础常识, redis的编译安装
这里说一个重点, README. 走到哪里, 不懂了, 先看readme.
第二个重点: 看脚本, 比如, 我的redis有几个后台启动的脚本server-install, 这个工具怎么用?
- 在根目录README中告诉我们了, 这是一个后台启动脚本
- 脚本怎么用, vi server-install.sh进去看看

第14条是: ./install_server.sh
一、为什么每次都要执行make
其实make时, 文件夹下一定有一个文件叫Makefile
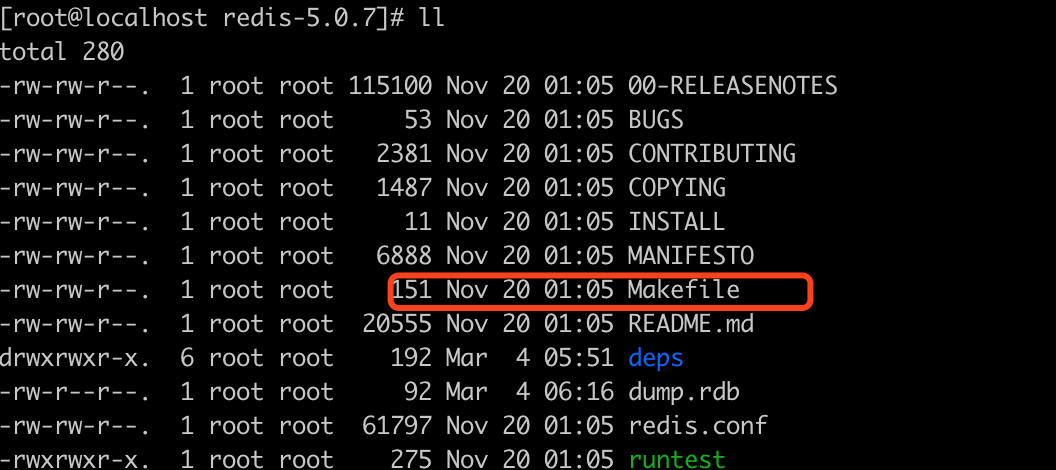
redis下载下来就有Makefile文件, 但nginx下载下来的时候没有这个文件, 我们要执行./configure来生成makefile文件
这就是为什么有些软件安装要直接使用make,而有些要先试用configure
二、strace工具和redis 的copy-on-write原理
strace : 监控系统内核进程的工具
首先, 讲一个工具strace. Linux的一个进程工具
这个工具的作用是: 用来最终redis的进程
可以参考这个文章: https://www.linuxidc.com/Linux/2018-01/150654.htm
比如,我们要追踪redis启动后的进程
strace -ff -o /usr/local/ooxx/out ./src/redis-server
#ff: 表示追踪所有的进程和线程
#-o: 表示日志输出的文件路径下的文件名 out是一个文件名的前缀, 如果有多个进程或线程, 以out开头redis成功启动后,进程id是16023
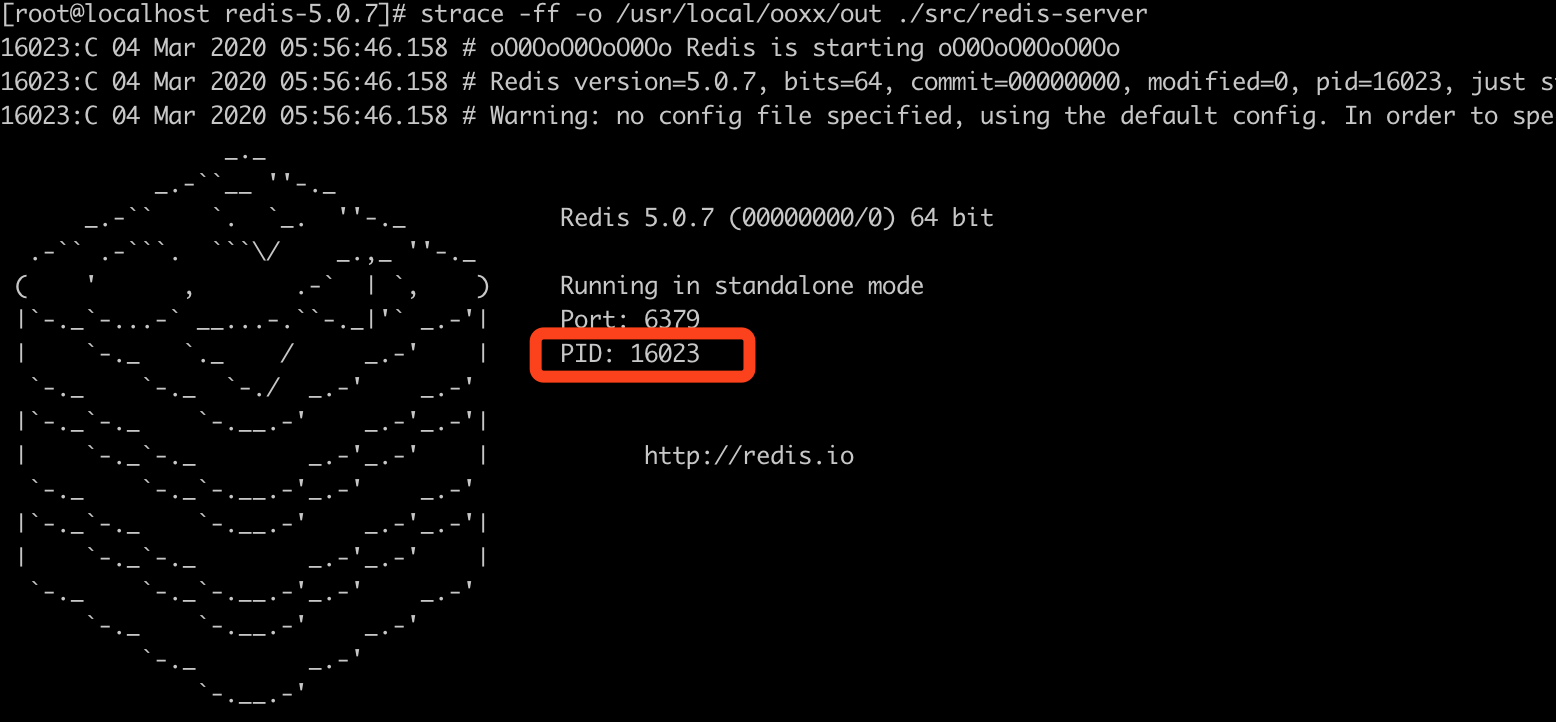
我们去 /usr/local/ooxx目录下查看进程文件, 我们看到有这样四个文件
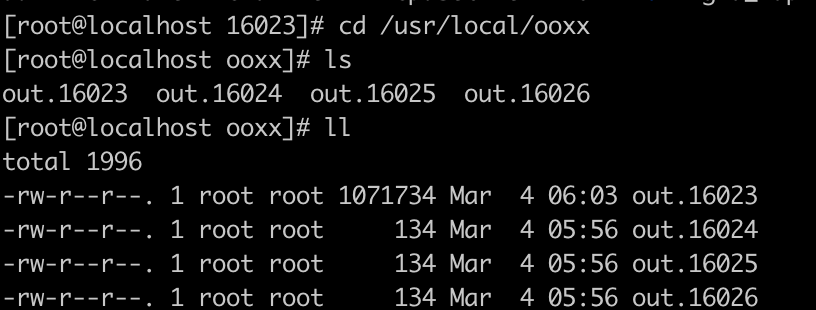
这里在介绍一个操作系统内核的命令/proc

proc这是一个操作系统内核
16023: 是我们启动的线程
他里面有一个task目录: 这里面是16023下启动的工作进程和线程
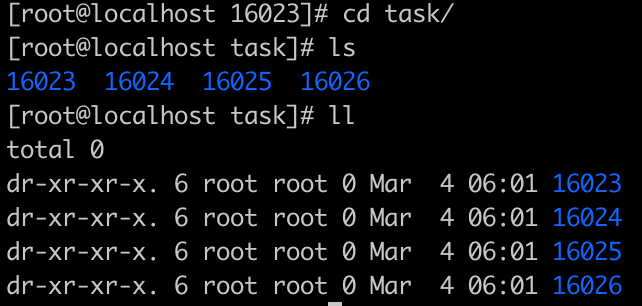
我们看到有4个工作的线程
和/usr/local/ooxx/下out的输出是一样的
下面举例:
redis持久化数据到磁盘的时候, 会新开一个进程. 然后用新的进程去执行持久化的操作. 我们用strace来追踪一下这个新创建的进程
第一步: 打开客户端, 执行bgsave

然后查看redis打印的日志输出
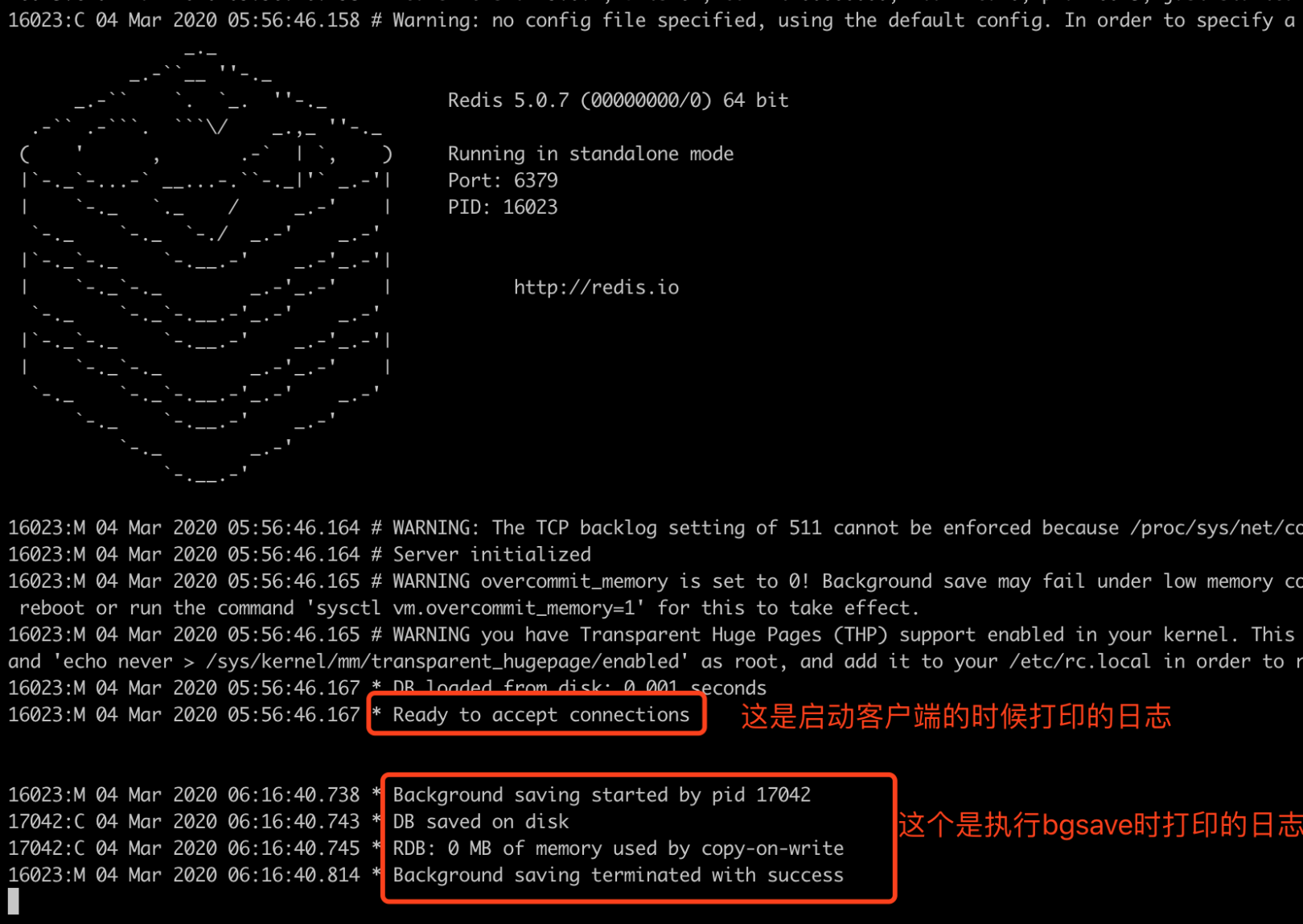
我们来分析一下执行bgsave打印的日志
Background saving started by pid 17042: 后台保存开始, 在17042这个进程上. 这个进程之前没有, 是新创建的
DB saved on disk: 数据已经保存到磁盘上
RDB: 0 MB of memory used by copy-on-write: 0M内存数据使用copy-on-write的方式被使用
Background saving terminated with success: 保存成功, 进程中断首先这里创建了一个新的线程17042.
我们来看看,是不是创建了一个新的线程

这个进程怎么来的呢? 肯定是主进程创建的, 我们来看看. vi out.16023.

果然有17042这个进程. strace中输出的每一行都是一句命令. 我们看看创建17042这个进程使用的是什么命令? clone
这是redis后台执行持久化时使用的方式: copy-on-write.
那么, 什么是copy-on-write呢? copy-on-write的原理.
redis有一个主进程, 在写数据, 这时候有一个命令过来了, 说要把数据持久化到磁盘.

我们知道redis的worker是单线程的, 如果要持久化这个行为也放在单线程里, 那么如果需要持久化数据特别多, 将会影响用户的使用. 所以单开一个进程专门来做持久化的操作.
那么写数据, 写什么呢? 肯定是要把redis内存中的数据写入. 这时候, 其实redis内存中的数据保存的是一个虚拟地址. 他真实指向的是物理内存的地址(绿色部分)
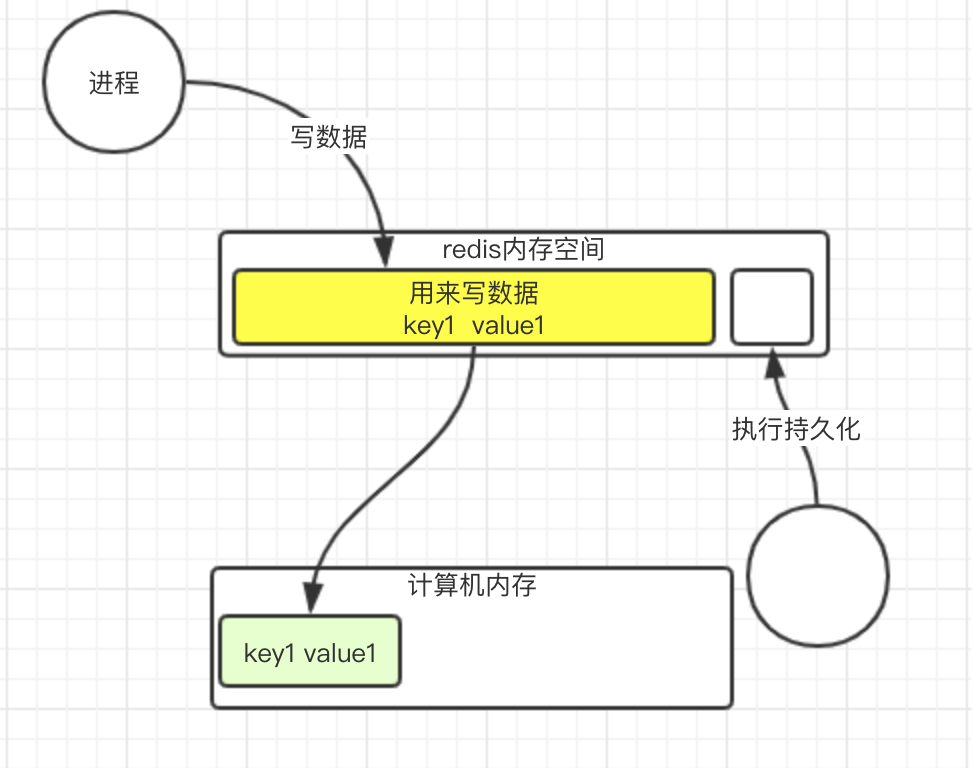
这时候, 要拷贝, 就是把真实数据的地址拷贝一份到需要持久化的进程中

其实持久化进程这个时候只是指向了数据的地址, 内存消耗并不多. 如果这时候, 原来的数据修改了, 怎么办呢?
redis会开辟一块新的空间, 让写数据的地址指向新的空间
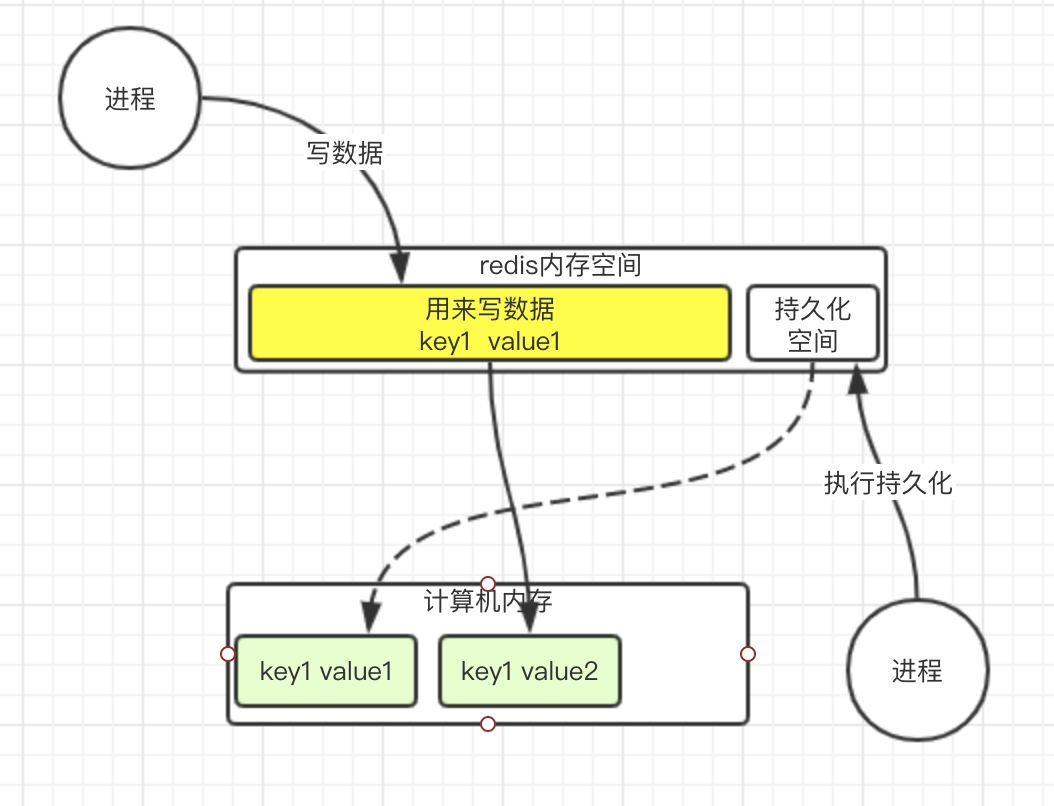
这样就不会影响持久化进程需要持久化的数据了.
这就是copy-on-write机制