Redis Scan返回数据量大于Limit的Count原因分析
Redis所有的Key都存储在一个大字典中,与JAVA的HashMap类似,是一个一维数组二维链表的结构,key会按算法取模计算的值挂到一维数组对应的值的索引的链表下。如下图:
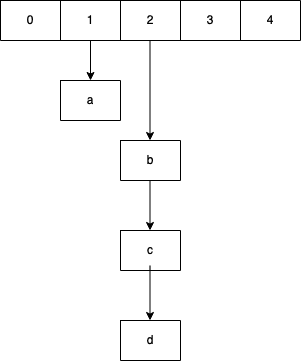
scan指令返回的游标就是第一维数组的位置索引,limit参数表示需要遍历的索引数量,不考虑字典扩容缩容的话,遍历将直接按一维数组的下标进行遍历。遍历的结果可能多可能少,因为不是所有的索引位上都会挂接链表,索引位上挂的链表的元素数量也可能有多个。每次遍历会将limit数量的索引位上挂接的所有的链表元素进行模式匹配过滤一次性返回给客户端。
我这次遇到的问题,是我每次通过scan获取匹配元素进行处理,但是为了不影响集群的性能,所以限制每次处理的元素不超过1024个,每次scan的数量限制为256个,但是程序跑着却突破了1024的这个限制,我就很纳闷,为什么我每次只scan256个,竟然会突破1024这个数量的限制,打了断点查看,一次scan竟然scan出来了2100多个元素,而且这2100个元素都是在一个位置上的。这个场景理论上只会在数据量特别大的情况才能够出现。为了找原因,翻redis的文档并没有翻到点上,看scan命令的说明也没看出个所以然来,然后就翻翻书,在《Redis深度历险 核心原理与应用实践》这本书上翻到了自己能够理解的说明。