文章系转载,便于整理和分类,原文地址:https://www.jianshu.com/p/59fe1eec0c36Redis4.0 PSYNC2介绍
PSYNC是Redis 4.0版本之前的主从同步协议。
在PSYNC协议中,主库维护一个同步bufferrepl_backlog(积压缓冲区),用以保存已经发送给从库的Redis命令;从库保存了主库的runid以及与主库同步的偏移量repl_offset。如果主从之间的网络断开再恢复(主从库均未重启),从库同步偏移量repl_offset在主库的repl_backlog之内,那么主从之间不需要全同步,只需要做增量复制。
PSYNC协议主要是为了解决网络抖动问题带来的主从全同步。在日常运维redis过程中,只要合理设置repl_backlog_size就可以利用PSYNC协议解决网络抖动带来的全量同步。
但是PSYNC也有一些缺陷。比如发生故障转移时,PSYNC处理的不够好。
用一主两从故障转移举例说明。拓扑结构如下:S1 --> M <-- S2。当M宕机时,将S1提升为新主库。此时无论S2或者M想成为新主库的从库,都必须做全量同步。这导致一发生故障转移,就必须做全量同步,这是不合理的。而且也对运维和集群性能产生非常大的影响。
同样的其他拓扑结构也会导致一样的问题,总结一下:
- 在链式一主两从结构中,
M <-- S1 <-- S2,当S1不可用,S2直连M时,S2和M需要做全同步; - 在树状一主两从结构中,
S1 --> M <-- S2,当M不可用,S2做S1的从库时,S2和S1需要做全同步; - 在一主一从的结构中,
M <-- S,当主从角色互换时,需要做全同步。
其次PSYNC对重启的支持也不好。一旦发生重启,即使不变更主从关系,也会发生全量同步。
在以上情况中,如果所有实例保存的数据都相同,完全可以不需要进行全同步。所以Redis 4.0版本改进了复制协议PSYNC2,尽量使得全同步不要出现。
PSYNC2
PSYNC2解决了上面的问题(图片来源于网上)。
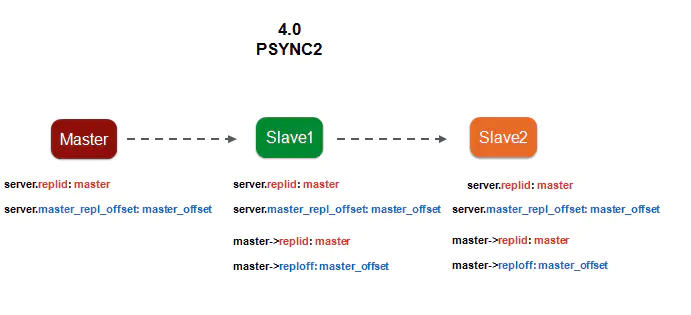
- 在建立主从复制关系时,
master会将自己的replid传递给slave,slave会把自己的replid更新为master的,这样逐级传递下去。最终master、slave1、slave2的server.replid全部一样,都是master的replid。 - 主从复制建立完成之后,这条复制链上所有的数据都由
master产生,也就是说master、slave1、slave2的offset也全都匹配得上。
那么在具体看一下pysnc2如何解决之前的问题。
- 在链式一主两从结构中,
M <-- S1 <-- S2,当S1不可用,S2直连M时,S2和M需要做全同步; 通过前面1,2项可以看出,M和S2具有相同的replid,并且offset也可以匹配得上,此时就可以直接进行增量同步,避免了全量同步的开销。 - 在树状一主两从结构中,
S1 --> M <-- S2,当M不可用,S2做S1的从库时,S2和S1需要做全同步; 当S1变更为主时,原来master的replid,offset不会丢弃,而是会保存在replid2和second_repl_offset中,参与匹配。那么S2的replid,offset都能从新主中找到replid2,并且和新主的second_repl_offset也匹配的上,就可以直接进行增量同步,避免全量同步的开销。 - 在一主一从的结构中,
M <-- S,当主从角色互换时,需要做全同步。 当S变更为主时,原来master的replid,offset不会丢弃,而是会保存在replid2和second_repl_offset中,参与匹配。那么M的replid,offset都能从新主中找到replid2,并且和新主的second_repl_offset也匹配的上,就可以直接进行增量同步,避免全量同步的开销。
其次、实例的repl-id和repl-offset保存到RDB文件中,保证从库重启之后,依然可以进行半同步。
PSYNC2只是一定程度上弥补psync的缺陷,当超过second_repl_offset,依然会进行全量同步。
所以在引进新功能的同时,也要注意合理设置repl-backlog-buffer大小。
实现细节: