简介
客户端缓存是Redis6众多新特性中比较实用的一项新功能,我们看看官方文档,了解一下它的作用:
客户端缓存是一种用于创建高性能服务的技术,它可以利用应用服务器上的可用内存(这些服务器通常是一些不同于数据库服务器的节点),在这些应用服务端来直接存储数据库中的一些信息。
与访问数据库等网络服务相比,访问本地内存所需要的时间消耗要少得多,因此这个模式可以大大缩短应用程序获取数据的延迟,同时也能减轻数据库的负载压力。
看到这,我心想这不是和其他本地缓存Guava、Caffeine啥的一样吗,换汤不换药,都是使用的应用服务的内存罢了。要说有什么好处,可能就是我在项目中能少引入一个中间件了。
不过,我这点浅薄的猜想,在看完客户端缓存的具体应用模式后,彻底被颠覆了。
两种模式
在了解了客户端缓存的基本功能后,我们来看看它的两种基本应用模式。Redis的客户端缓存支持被称为tracking,个人感觉翻译为对key的追踪就很好理解,它具有两种模式:
- 默认模式,服务端会记录某个客户端具体访问过哪一些
key,当这些key对应的值发生变化时,会发送失效消息给这些客户端。这个模式会在服务端消耗一些内存,但是发送失效消息的范围,被限制在了客户端存储了的key的集合范围内 - 广播模式,服务端不会再记录某个客户端访问了哪些
key,因此这个模式不消耗服务端的内存。取而代之的是,客户端需要订阅key的特定前缀,每当符合这个前缀的key对应的值发生改变时,客户端都会收到通知消息
看到这里,它和我们之前使用的两级缓存之间差异,是不是已经初露端倪了呢?如果还不熟悉两级缓存的架构,那么可以先来看看下面的这张图:

这种架构在理论上看起来不错,但是实际使用起来需要注意的点不少,尤其是在分布式模式下,需要保证各个主机下的一级缓存的一致性问题,回想一下我们原先的解决方案,可以使用redis本身的发布/订阅功能来实现:

而客户端缓存的出现,大大简化了这一过程。我们以默认模式为例,看一下使用了客户端缓存后的操作过程:
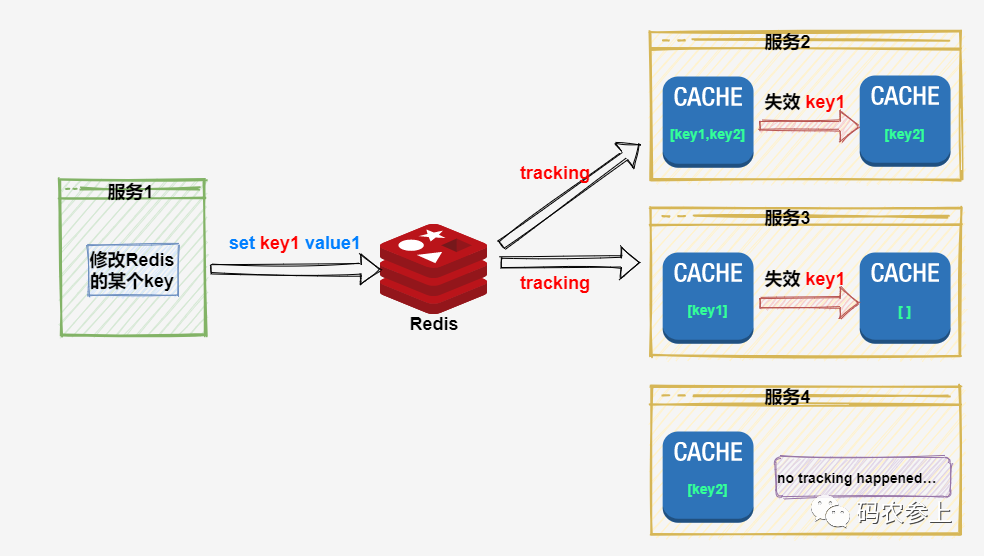
相比原先的发布/订阅模式,我们可以看到明显的优势,使用客户端缓存功能后,我们只需要单纯的修改redis中的数据就可以了,手动处理发布/订阅消息的这一过程可以完全被省略。
优势
到这里,在了解了客户端缓存的基本功能与两种模式后,我们来对比一下,和传统的只使用redis做远程缓存、以及使用整合后的两级缓存相比较,客户端缓存具有什么样的优势。
- 当应用的服务端存在缓存时,会直接读取本地缓存,能够减少网络访问上造成的延迟,从而加快访问速度
- 同时也能减少访问redis服务端的次数,降低redis的负载压力
- 在分布式环境下,不再需要通过发布订阅来通知其他主机更新本地缓存,来保证数据的一致性。使用客户端缓存后,它所具有的原生的消息通知功能,能很好地支持作废本地缓存,保证之后访问时能取到更新后的新数据
误区
在开始演示客户端缓存的使用之前,我们先来纠正一个误区。
虽然这个新特性被称为客户端缓存,但是redis本身不提供在应用服务端缓存数据的功能,这个功能要由访问redis的客户端自己去实现。
说白了,也就是redis服务端只负责通知你,你缓存在应用服务本地的这个key已经作废了,至于你本地如何缓存的这些数据,redis并不关心,也不负责。
功能演示
下面将通过一些实例来进行演示,本文代码的运行前提条件是你已经装好了Redis6.x版本,linux环境下可以直接从官网下载后编译安装,windows环境下的安装可以参考 手摸手教你在Windows环境下运行Redis6.x 这篇文章。
概念上的东西我们也大体了解了,下面我们分别来看一下客户端缓存具体实现的三种模式(至于为什么多了一种,后面再来细说)。在正式开始前,强烈建议大家先花个十几分钟了解一下 Redis6底层的通信协议RESP3,否则在看到具体的通信内容时可能会存在一些疑问。
首先做一下准备工作,通过telnet连接redis服务,并切换到resp3协议模式:
telnet 127.0.0.1 6379
hello 31、默认模式
在使用客户端连接到redis服务后,需要先通过指令开启tracking模式的功能,因为在客户端连接后这个选项是默认关闭的,会无法收到失效类型的push消息:
#开启
client tracking on
#关闭
client tracking off当开启tracking后的默认模式下,redis服务端会记录每个客户端请求过的key,当key对应的值发生变化时,会发送失效信息给客户端。简单总结一下,也就是说这个模式能够生效的必要前提条件有两个:
- 开启
tracking - 客户端访问过某个key
下面我们还是在telnet中来模拟一下这个过程,分别启动两个redis客户端,在client1中先执行get命令后,再在client2对相同的key执行set操作修改它的值,之后就会在client1中收到push类型的消息。
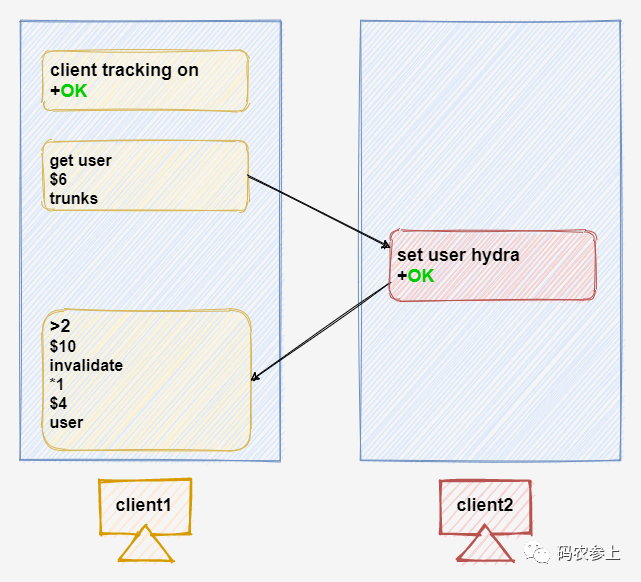
push类型的消息我们在RESP3中介绍过了,这里简单再唠叨两句:
>2
$10
invalidate
*1
$4
user起始的第一字节>表示该消息为push类型,后面消息体中包含了两部分内容,第一部分表示收到的消息类型为invalidate,也就是作废类型的信息,第二部分则是需要作废的key是user。
除此之外,当一个缓存的key到达失效时间导致过期,或是因为到达最大内存,要使用驱逐策略进行驱逐时,也会对客户端发送PUSH的消息。下面以缓存的key过期为例:
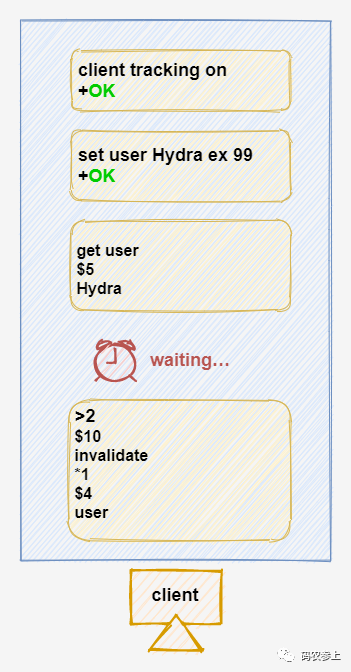
另外,对于单个key来说,这个tracking消息只会对客户端发送一次,当第二次修改该key所对应的值后,客户端不会再收到tracking的消息。只有对这个key再执行一次get命令,之后才会再次收到tracking消息。
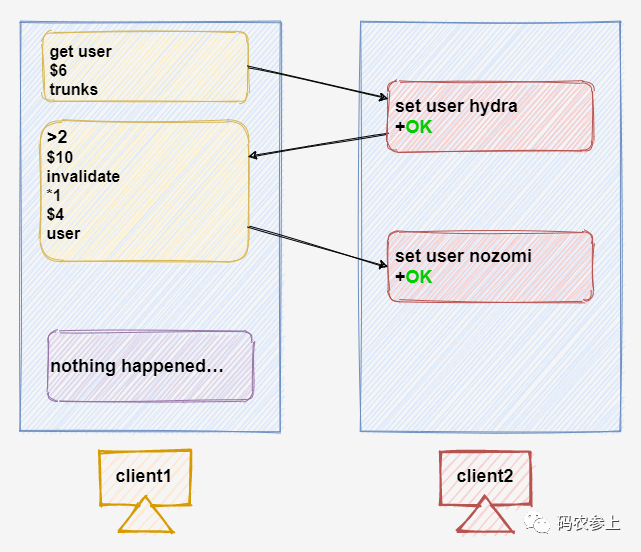
默认模式虽然使用起来简单,但是需要在服务端存储客户端的访问数据,记录哪些key被哪些客户端访问过。如果访问的不是少量的热点数据的话,可能会占用大量redis服务端的内存空间。应对这种情况,可以试一试下面要介绍的广播模式。
2、广播模式
在广播模式BCAST下,redis服务端不再记录key的访问情况,而是无差别地向所有开启tracking广播的客户端发送消息。这样一来,好处就是不需要浪费redis服务端的内存进行记录,但是坏处就是客户端可能会收到过多的消息,其中可能还会包含自己不需要的一些key。
在使用前,需要先通过命令开启广播模式:
client tracking on bcast下面,我们通过一个例子来进行广播模式的使用演示:
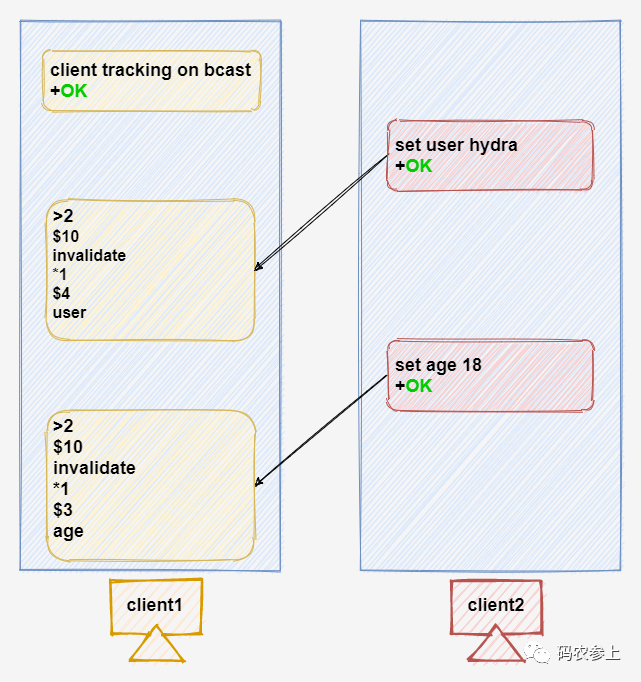
可以看到在开启广播模式后,只要在client2中修改了key对应的值,在client1中都会收到作废消息,而不管client1之前在本地是否进行过缓存。
并且,另外一点和默认模式不同的是,广播模式是能够重复多次收到一个key的失效消息的,因为服务端没有记录,所以只要有key发生了修改,客户端就会收到失效消息。
这时候,有的小伙伴可能就要问了,如果我不想收到这么多没用的冗余消息,有没有什么办法进行一下过滤或精简呢?
答案是可以的,在广播模式下,客户端可以只关注一些特定前缀的key,表示我只需要接收这些前缀的key,其他的就不要发给我了。命令格式如下:
client tracking on bcast prefix myprefix再来看一下使用过程的示例:

可以看到,在设置了只关注以order:作为前缀的key后,成功过滤掉了user的失效消息。从这个角度来看,也要求了我们在缓存一个类型的数据时,都以相同的单词作为前缀,规范了我们在使用缓存中对key的命名规则。
至于在业务中具体要使用哪种模式,可能更多的需要进行一下权衡。看一下你究竟是能忍受占用更多redis服务端的内存,还是能够忍受收到大量不需要的失效消息。
3、转发模式
默认模式和广播模式的生效,都要在开启RESP3协议的前提下,具体原因看过上面的例子大家应该也都清楚了,因为要使用tracking的话,就必须要借助到RESP3协议中的新的push消息类型。
那么如果客户端还是使用的旧版本RESP V2的话,也想要体验这一功能,应该如何进行改造呢?
不得不说redis6的开发者想的还是蛮全面的,为了适配RESP V2,专门设计了一种新的转发模式,允许使用旧版本协议的客户端通过Pub/Sub发布订阅功能来接收key的失效信息。

从上面这张图可以看到,转发模式的核心就是redis服务端会将原先push类型的tracking信息,转发到订阅了_redis_:invalidate这一信道的被指定的客户端上。
我们来梳理一下上面的流程,首先在client1需要使用指令开启转发模式:
client tracking on bcast redirect [client-id]相对广播模式,多了两个参数,redirect表示为转发模式,后面的client-id表示消息要发送给哪一个客户端,客户端的id可以在client2上通过client id指令获取。
在client2中,则需要订阅指定的信道:
subscribe _redis_:invalidate其实说白了,转发模式还是使用的发布订阅功能罢了,只不过redis帮我们解放了双手,把发送消息的工作由自己完成了。整个操作的流程如下图所示:
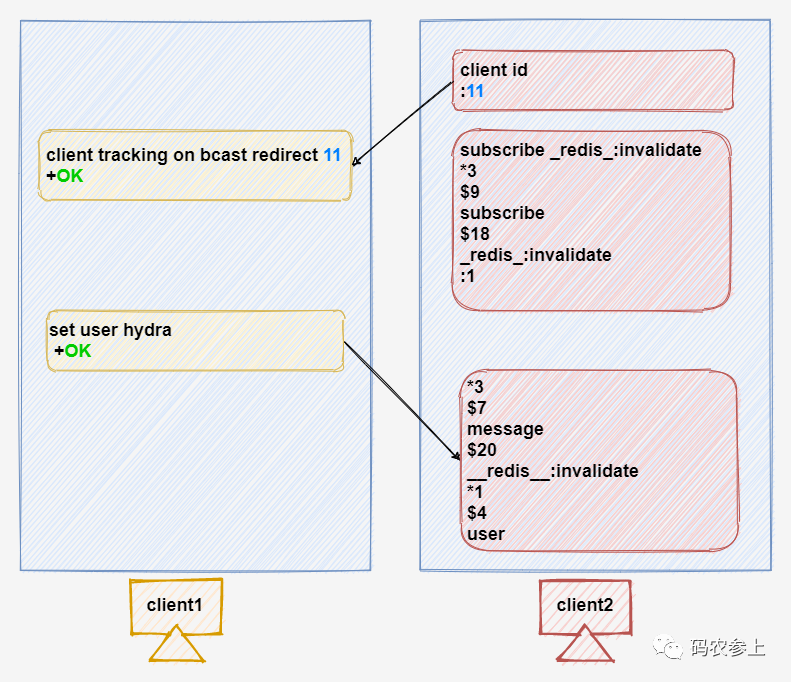
可以看到,client2中收到的消息格式与之前的push类型消息不同,是一条RESP V2中多条批量回复格式的消息,表示的含义同样是收到的key已经作废掉了。
需要注意的是,虽然说开启转发模式的指令中也带了一个bcast,但是它和广播模式有着非常大的区别。在转发模式下,key的作废消息只能被转发到一个客户端上,如果先后执行两条指定转发指令,那么后执行的指令会覆盖前一指令中转发的client-id。
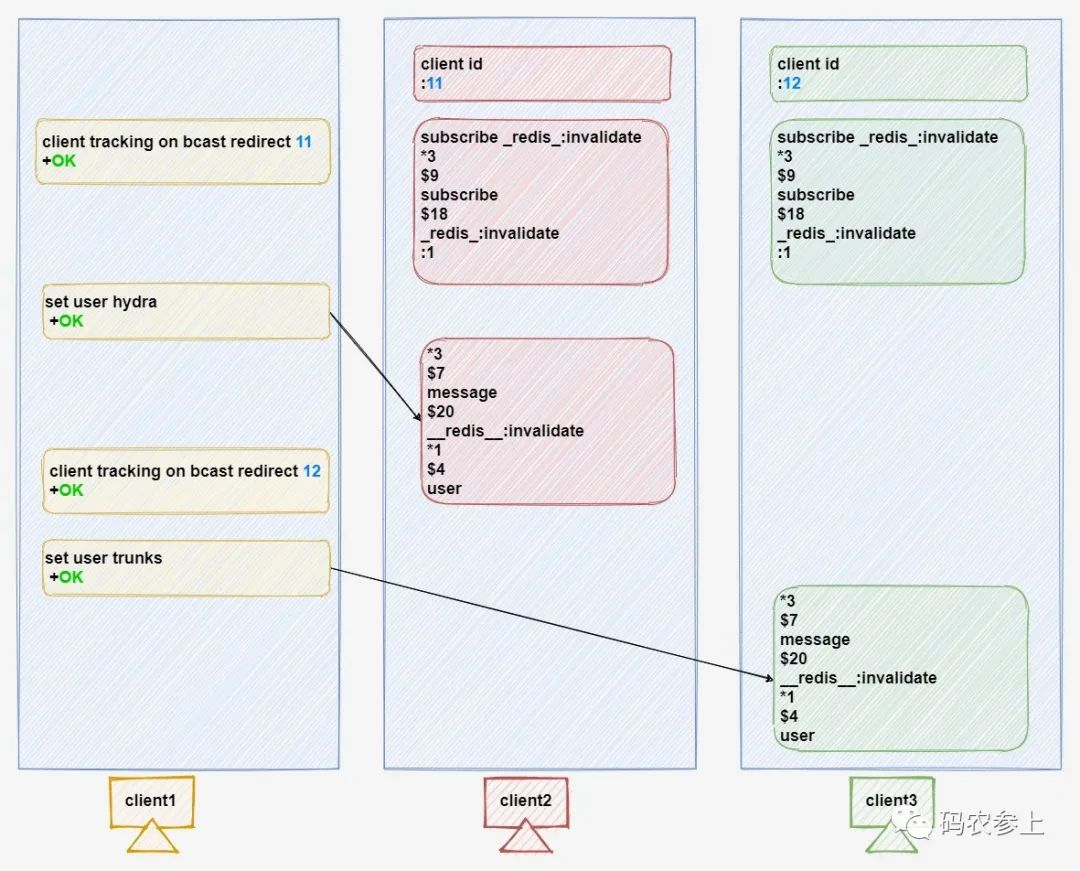
看到这里是不是多少感觉这个转发模式有点鸡肋,毕竟实际的业务场景中很有可能会有多个客户端的存在,只能转发一个实在是有点说不过去了。不过,也有可能作者就是这么设计,留点缺陷,好让大家更快地拥抱RESP3……
总结
好啦,到这里客户端缓存的基本理论和使用就介绍的差不多了,不得不说,Redis6的这个新特性确实给了我们眼前一亮的感觉。从这个新特性也可以看出,Redis大有把缓存从服务端的局限中挣脱出来,染指向客户端,一统缓存江湖的意味。
不过这个过程应该并不简单,就像我们前面说的,毕竟只有Redis服务端还不够,还需要优秀的客户端进行支持才行。
那么下一篇文章,我们就来从实战角度,看看如何改造客户端,让client-side caching能在项目中落地开花。
这次的分享就到这里,我是Hydra,下篇文章再见。