Redis6.0新特性-Thread/IO多线程
一、背景
目前快手有70w+的Redis实例,在线上的Redis集群,我们经常会碰到以下的一些情况:
(1) 由于键值设计不合理或者业务特性导致的热点问题(集群整体QPS不高,但是集群内某个实例的请求特别高),严重影响业务侧请求的返回时间
(2) 集群内某个实例直连集群连接数过多,单线程模型处理缓慢,影响其他的请求
(3) 集群内某个实例网络不稳定后者pipeline个数较多,导致协议解析频繁调用,导致cpu时间占用过长,影响其他的客户端请求
以上这些问题,相信大家也都碰到过,那么这些问题与Redis的单线程模型又有什么关系?
1. 为什么Redis6之前是单线程设计?
首先,我们明确一点,Redis6之前的Redis4,Redis5并不是单线程程序。通常我们说的Redis的单线程,是指Redis接受链接,接收数据并解析协议,发送结果等命令的执行,都是在主线程中执行的。
Redis之前之所以将这些都放在主线程中执行,主要有以下几方面的原因:
- Redis的主要瓶颈不在cpu,而在内存和网络IO
- 使用单线程设计,可以简化数据库结构的设计
- 可以减少多线程锁带来的性能损耗
2. 什么是IO多线程?
既然Redis的主要瓶颈不在CPU,为什么又要引入IO多线程?Redis的整体处理流程如下图:
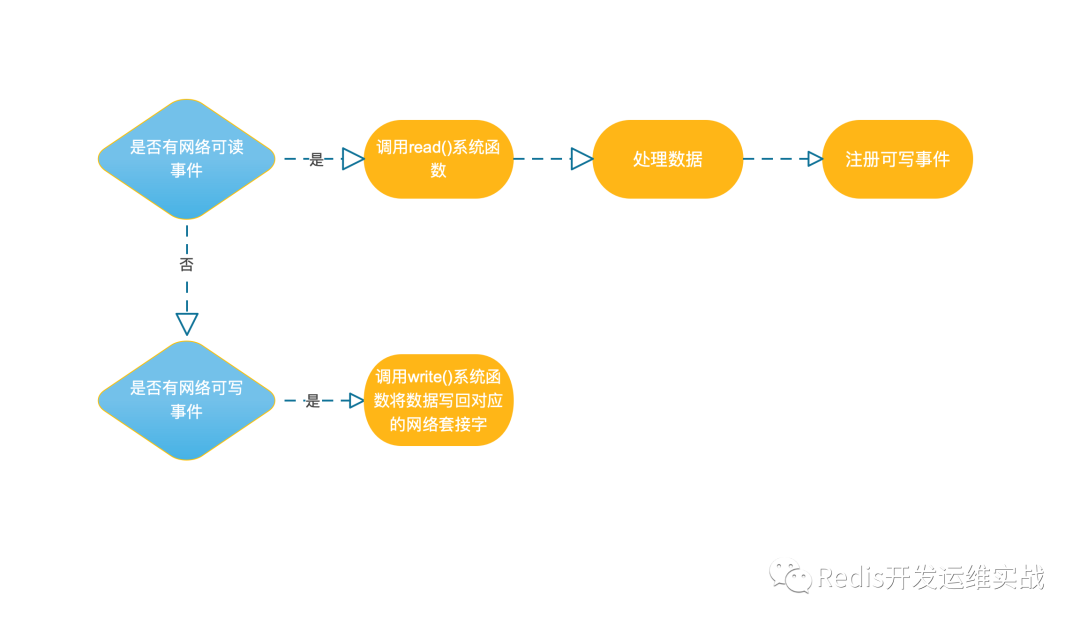
结合上图可知,当 socket 中有数据时,Redis 会通过系统调用将数据从内核态拷贝到用户态,供 Redis 解析用。这个拷贝过程是阻塞的,术语称作 “同步阻塞IO”,数据量越大拷贝的延迟越高,解析协议时间消耗也越大,糟糕的是这些操作都是在主线程中处理的,特别是链接数特别多的情况下,这种情况更加明显。基于以上原因,Redis作者提出了Thread/IO线程,既将接收与发送数据来使用多线程并行处理,从而降低主线程的等待时间。
二、Thread/IO整体流程及程序实现设计
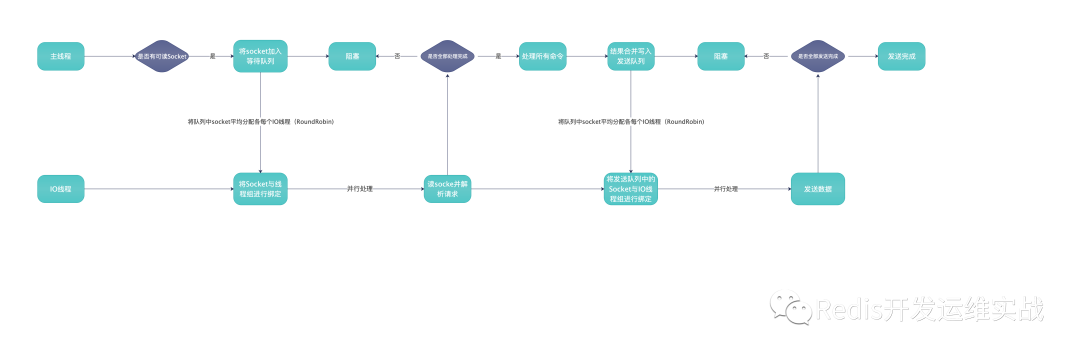
1.Thread/IO整体实现思路
(1).创建一组大小为io线程个数的等待队列,用来存储客户端的网络套接字。
(2).分均分配客户端网络套接字到等待队列中
(3).等待线程组接收解协议完毕或者发送数据完毕
(4).执行后续操作,然后跳转到第2步继续执行
2.Thread/IO涉及到的代码文件
关于IO多线程部分的代码,在src/network.c中。
3.Thread/IO整体流程图
三、关键代码流程详解
1.io线程的初始化
Redis多线程相关线程的初始化顺序

初始化相关流程图及代码创建线程流程图
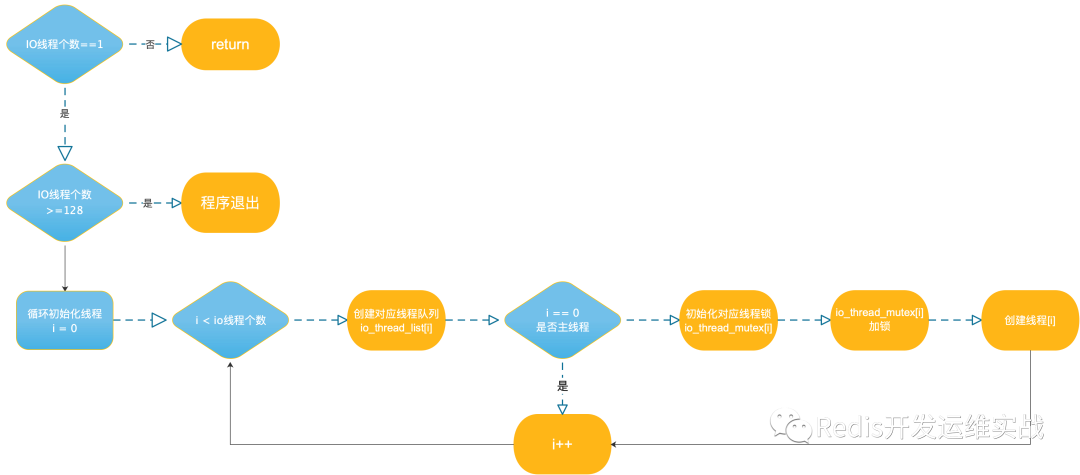
创建线程代码具体位置
src/network.c: initThreadIO(void)src/network.c: IOThreadMain(void *)
2.readQueryFromClient部分
代码具体位置:src/network.c: readQueryFromClient(connection *)
void readQueryFromClient(connection *conn) {
client *c = connGetPrivateData(conn);
int nread, readlen;
size_t qblen;
/* Check if we want to read from the client later when exiting from
* the event loop. This is the case if threaded I/O is enabled. */
if (postponeClientRead(c)) return;
/
/* 单线程解析部分代码 */
...
}int postponeClientRead(client *c) {
if (io_threads_active &&
server.io_threads_do_reads &&
!ProcessingEventsWhileBlocked &&
!(c->flags & (CLIENT_MASTER|CLIENT_SLAVE|CLIENT_PENDING_READ)))
{
c->flags |= CLIENT_PENDING_READ;
listAddNodeHead(server.clients_pending_read,c);
return 1;
} else {
return 0;
}
}由上面部分的代码,可以得知客户端要使用io多线程必须满足的条件有:
io多线程已经激活
io多线程允许read
没有阻塞的处理事件
客户端不是主节点、从节点、已分配的延迟接收客户端
3.处理读取待分配任务
处理读取待分配任务流程图
处理读取待分配任务代码
src/networking.c: handleClientsWithPendingReadsUsingThreads(void)
4.处理写待分配任务
写分配任务具体流程同读分配流程大同小异,看参照上图阅读具体的代码实现,代码位置:
src/networking.c: handleClientsWithPendingWritesUsingThreads(void)
5.IO线程的动态开与关
主线程中整体读与写的逻辑流程图

具体代码位置:src/server.c: beforSleep(struct aeEventLoop *)
IO线程的开关循序流程图
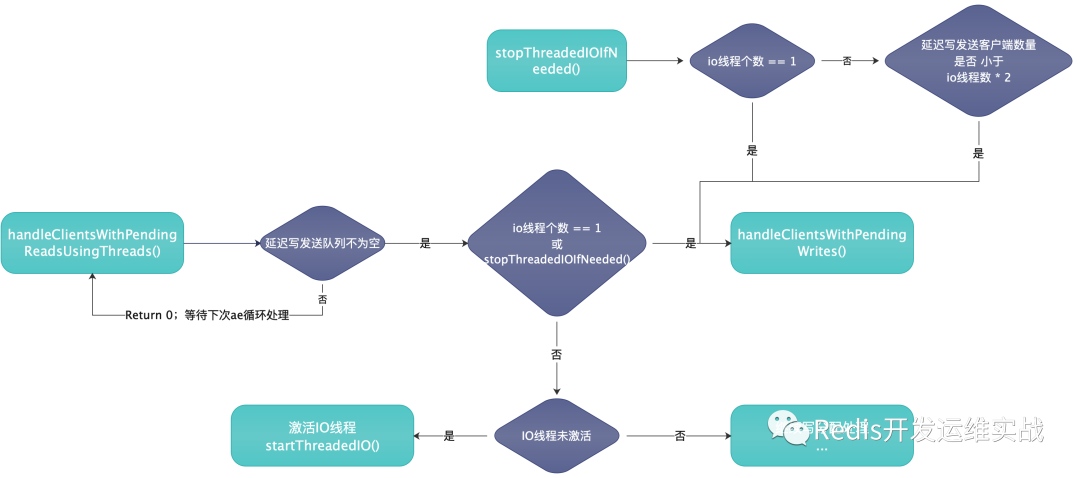
由上图可知,IO线程的开关,实际取决于延迟发送客户端的数量是否小于IO线程数*2,否则IO线程一般都处于阻塞状态(即使设置了IO多线程)。
具体代码位置:
src/networking.c: handleClientsWithPendingWritesUsingThreads(void)src/networking.c: int stopThreadedIOIfNeeded(void)src/networking.c: startThreadedIO(void)
四、配置文件对应配置项说明
| 配置项 | 说明 | 默认值 | 备注 |
|---|---|---|---|
| io-threads | 配置redis的io线程个数 | 4 | 最大不超过128,且默认不开启 |
| io-threads-do-reads | io线程负责read | no | 默认io线程只负责发送数据,既wirte数据返回给客户端 |
五、Thread/IO性能测试
1.测试方法与测试指标
本次测试,采用vire-benchmark工具进行压测。redis-server与vire-benchmark对应压测参数如下:
(1)redis-server
| 配置 | 说明 | 值 |
|---|---|---|
| io-threads | io线程的数量 | [1,2,3,4,5,6,7,8] |
| io-threads-do-reads | io线程是否负责接收数据 | yes |
(2) vire-benchmark
| 压测项 | 值 |
|---|---|
| 客户端数量 | [1,10,50] |
| payload大小 | [20,64,256,1024,2048,8192] |
| pipeline个数 | [10,50,100,500] |
| 压测命令 | get,set,mget_10,mget_100,mset,lpush,rpush,lpop,rpop,lrange_10,lrange_100,sadd,spop,hset, hincrby,hget,hmset,hmget,hgetall,zadd,zrem,pfadd,pfcount |
2. 测试结果分析
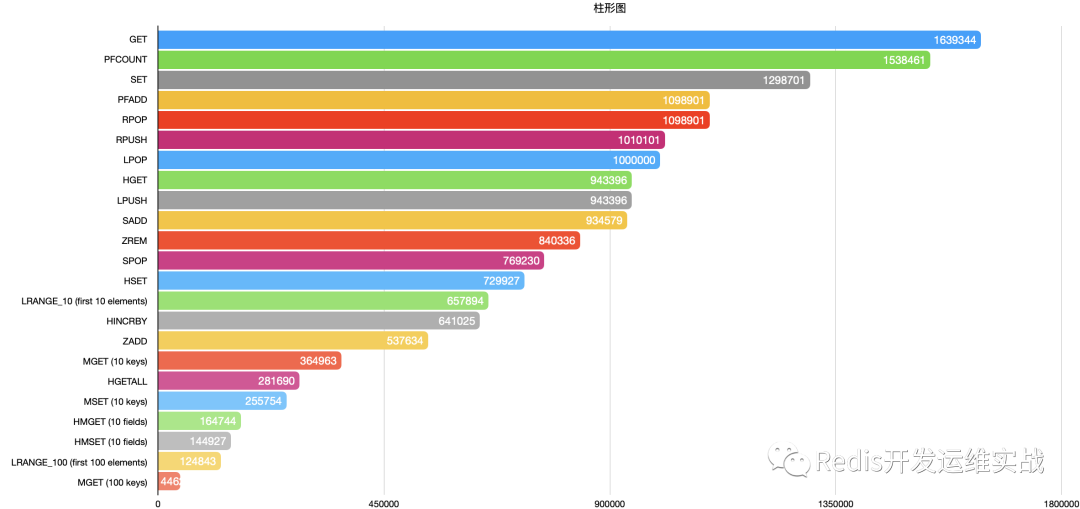
(1) 各个命令的极限QPS
注:压测结果不考虑客户端数量,payload大小,pipeline个数,只是直观展现Redis6开启io多线程后,针对各个命令所能达到的极限QPS。
(2) IO线程数量与极限QPS的关系
在极限QPS的测试结果中,client个数基本上都为1,不具备实际意义,再结合线上实际业务情况,选取GET,client_count(50),payload(20),pipeline(50)作为结果分析的参考基准。
Get,client_count(50),payload(20),pipeline(50)

由上图可知,针对Get等简单命令,IO线程也并不是越多越好,这也符合代码中的自旋锁的实现逻辑。但是IO多线程,确实能够再一定程度上提升QPS,但是效果并不是很明显。
Get,client_count(50),pipeline(50)
| 描述 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| payload(20) | 1234567 | 1282051 | 1315789 | 1562499 | 1204819 | 1408450 | 1265822 | 1282051 |
| payload(64) | 1250000 | 1234567 | 1315789 | 1333333 | 1176470 | 1388889 | 1333333 | 1428571 |
| payload(256) | 1123595 | 970873 | 1190476 | 1351351 | 1369863 | 1298701 | 1369863 | 1333333 |
| payload(1024) | 694444 | 806451 | 757575 | 793650 | 847457 | 833333 | 900900 | 862069 |
| payload(2048) | 431034 | 357142 | 381679 | 400000 | 446428 | 442477 | 485436 | 467289 |
| payload(4096) | 218818 | 232558 | 264550 | 247524 | 255754 | 237529 | 239808 | 265252 |
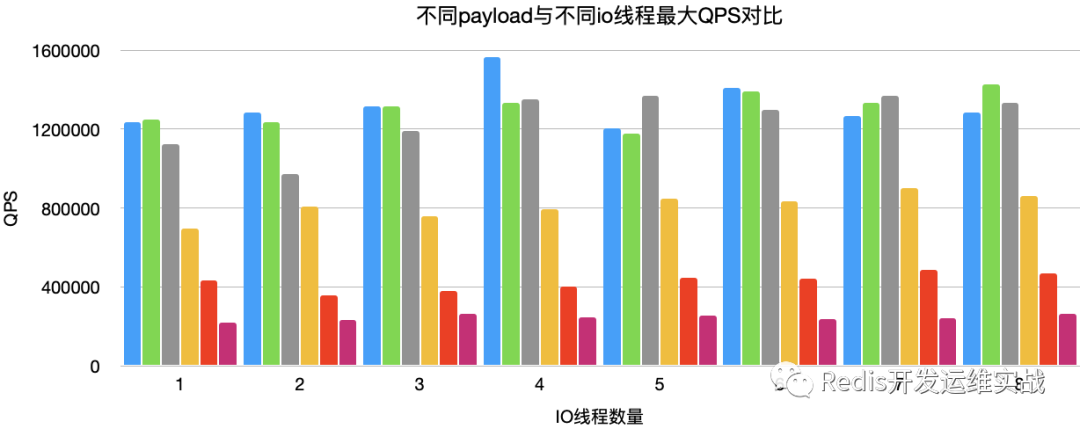
由上图可知,IO多线程对payload较大请求,处理效果提升明显,但是当payload提高到2048左右时,提升效果不明显。
Get,pipeline(50),bytes(20)
| 描述 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| client(1) | 1408450 | 1388889 | 1449275 | 1470588 | 1515151 | 1515151 | 1538461 | 1492537 |
| client(20) | 1408450 | 1408450 | 1315789 | 1351351 | 1515151 | 1449275 | 1538461 | 1449275 |
| client(50) | 1234567 | 1282051 | 1315789 | 1562499 | 1204819 | 1408450 | 1265822 | 1282051 |
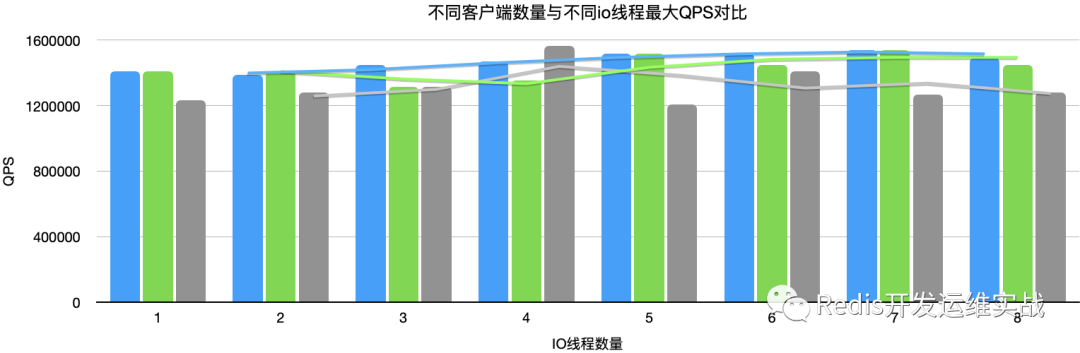
对于客户端数量而言,IO多线程针对多个客户端有一定提升,但是效果不是很明显。上图也可观察到,当客户端数量提高到50左右时,IO线程越多,QPS反而成下降趋势。
Get,client_count(50),payload(20)
| 描述 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| pipeline(10) | 757575 | 869565 | 1010101 | 934579 | 917431 | 1123595 | 1010101 | 1052631 |
| pipeline(50) | 1234567 | 1282051 | 1315789 | 1562499 | 1204819 | 1408450 | 1265822 | 1282051 |
| pipeline(100) | 1470588 | 1298701 | 1369863 | 1408450 | 1250000 | 1369863 | 1428571 | 1298701 |

由上图可知,在pipeline个数较少时,qps随着IO线程数量增多缓慢增加,当pipeline个数大于50个以上,随着线程数的增加,QPS成缓慢下降趋势。
3. 测试结果总结
IO线程总体提升效果并不是非常明显,以基准结果为例,当IO线程为4时,较单线程在同条件下,QPS提升25%左右
IO线程,对val与pipeline较大的操作,有明显的提升,当IO线程为4时,较单线程在同条件下,QPS最大提升30%左右,但随着val的增大,提升并不明显
对于多个客户端,IO多线程的提升并不明显
通过测试数据,发现Redis的IO多线程,在设置为4个时可达到最佳效率,到达最高QPS
六、使用Thread/IO注意事项
io-threads个数设置为1时,实际上还是只使用主线程
io-threads默认只负责write,既发送数据给客户端
io-threads的个数一旦设置,不能通过config动态设置
当设置ssl后,io-threads将不工作
通常io线程并不能有太大提升,除非cpu占用特别明显或者客户端链接特别多的情况下,否则不建议使用
io线程只能是读,或者写,不存在读写并存的情况(这点配置文档上没写,不知道作者是如何得出的结论,需要 参考源码看看)
Io线程的开关,实际取决于延迟发送客户端的数量是否小于IO线程数*2
七、线上当前Redis6的情况
注:KCC是快手内部Redis管控平台,目前管理70万Redis、Memcache实例,3000+ElasticSearch节点。由于实例数量庞大,热点问题不可避免,为此上Redis 6也是刚需。1.KCC线上目前已上线30+,集群运行稳定,如需申请,在KCC平台请注明使用Redis6版本即可
2.改造代理内核源码,覆盖Redis5/6新增的全部命令,如:bitfield_ro、stralgo、zpopmin、zpopmax等
3.改造Redis 6升级工具,支持持Redis3、4、5、6任一版本升降。
4.由于键值设计不合理以及业务特性带来的热点问题,Redis单线程版本单个实例达到请求瓶颈,切换到Redis6版本后,单实例QPS可到20~30W+,效果符合预期,降低了业务高负载时的请求延时问题